
Seis grandes ideas que subyacen en la Web 2.0
https://eduteka.net/articulos/Web20Ideas
|
|
 Publicamos la traducción al español de apartes del informe
Publicamos la traducción al español de apartes del informe |
|
http://www.elpais.com.co |
|
|
|
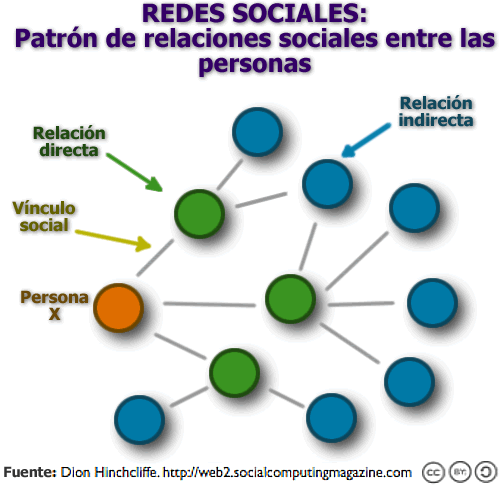
Por ejemplo, una persona X que pertenezca a una red social como LinkedIn, y cuente en esta con 334 contactos directos (relación directa - verde), podría llegar a tener 84.200 contactos producidos por sus contactos directos (relación indirecta - azul) y 3’465.100 contactos de tercer grado (esto es: amigos de los contactos indirectos de sus contactos directos). http://web2.socialcomputingmagazine.com/ |
|
|
|
En este mapa se puede apreciar claramente en qué consisten las llamadas Mash-ups: El mapa procede de Google Maps; los círculos representan los movimientos sísmicos registrados en los últimos 7 días (enero 17 al 23 de 2008) cuyos datos provienen de la respetada agencia gubernamental USGS; los símbolos azules representan los cráteres ocasionados por impactos de cuerpos celestes sobre La Tierra, datos puestos a disposición de toda la comunidad de Google Maps por un usuario de esta. |
|
|
|
En esta grafica se puede apreciar la distribución de las 10 principales categorías de mashups. |
|
|
|
Los dos extremos del espectro del Mashup, la diferencia entre ellos radica en las plataformas que comúnmente utilizan usuarios y desarrolladores para reutilizar y combinar datos. |
|
|
|
Esta topología de Internet muestra en marzo de 2001 cerca de 535.000 nodos de Internet y unos 600.000 enlaces. Fuente: Young Hyun, Cooperative Association for Internet Data Analysis [CAIDA] |
|
|
|
Las aplicaciones Web 2.0 apalancan explícitamente el Efecto de Red |
|
|
|
Cola Larga: distribución estadística que se aplica generalmente al comportamiento del mercado en la venta de productos. Las ventas de os más populares se encuentran concentrados en la parte izquierda de la gráfica (cabeza) y las de los menos populares se distribuyen hacia la derecha (cola) con frecuencias que se aproximan a cero. |
|
|
|
Descargue este documento en formato PDF (1.3MB)
http://www.eduteka.org/pdfdir/Web20Ideas.php
Ver además el documento “Entienda la Web 2.0 y sus principales servicios”
En la publicación anterior sobre Web 2.0 hicimos alusión al considerable nivel de especulación que existe para precisar a qué se hace referencia específica con la denominación de 2.0.
Lo que pretendemos en esta oportunidad es compartir con ustedes las reflexiones que hizo Paul Anderson para JISC, respecto a las ideas básicas que subyacen dentro del término “Web 2.0” y, en lo posible, elaborar las conjeturas hechas respecto a cómo el crecimiento acelerado de la Red (network) contribuyó al desarrollo y estallido de la burbuja de las “punto com” [1]. Esto último, importante de aclarar no solo para evitar su repetición, sino además, para tener una comprensión más amplia y real del papel que la Web 2.0 puede jugar en la educación.
Las Seis Grandes Ideas que abordaremos se basan en conceptos originalmente destacados por Tim O’Reilly en su escrito, ahora famoso, Qué es Web 2.0: Patrones de diseño y modelos de negocio para la siguiente generación de software. Estas nos ayudan a explicar y a entender el impacto tan grande que puede tener la Web 2.0. Resumiendo, estas ideas versan sobre la construcción de algo mayor a un espacio de información global; algo que tiene un componente social mucho más marcado ya que en esta, colaboración, contribución y comunidad son fundamentales. Esto ha llevado a que algunos piensen que ante nuestros ojos se está construyendo un nuevo tejido social. Cabe aclarar que estas ideas no son exclusivas de la Web 2.0, son el reflejo directo o indirecto del poder de la Red: los efectos curiosos y las topologías (patrones de interconexión) que a nivel micro y macro producen más de 1.200 millones de usuarios de Internet.
Estas ideas son:
- Producción individual y contenido generado por el usuario
- Aprovechamiento del poder de las masas
- Datos en una escala épica
- Arquitectura de Participación
- Efectos de la Red
- Apertura
1- PRODUCCIÓN INDIVIDUAL Y CONTENIDO GENERADO POR EL USUARIO
“Siempre imaginé el espacio informativo como algo en el que cualquiera
tiene acceso intuitivo e inmediato y no solamente para navegar, sino para crear”
Tim Berners-Lee [2]
El lema acuñado por la música rock de la generación punk “Eso lo puedo hacer yo” llevó a miles de personas a conformar bandas musicales y a escribir sus propias canciones.
Actualmente, con unos pocos clics del ratón (mouse) un usuario puede subir un video o una fotografía de su cámara digital a su propio espacio mediático virtual, etiquetarlo con palabras clave de su escogencia y poner el contenido a disposición de sus amigos o de la gente en general. Paralelamente, hay personas creando y escribiendo Blogs y trabajando conjuntamente para generar información mediante el uso de Wikies. Lo que han hecho esas herramientas es bajarle a la gente las barreras de entrada, siguiendo los pasos de la revolución de la auto edición de los años 80, que tuvo como detonantes la introducción de las impresoras láser y el software de autoedición, también llamado de diseño editorial, cuyo pionero fue Apple. Lo anterior ha generado un torrente de producción en la Web.
Recientemente, mucho del foco de atención de los medios respecto al crecimiento del fenómeno Web 2.0, se ha centrado en lo que se ha dado en llamar Contenido generado por el usuario (UGC, por su sigla en inglés). Algunos nombres alternativos para esta situación son auto publicación de contenido, publicación personal y auto expresión.
Y hablando de los medios masivos de comunicación, ellos están pasando por un período de cambio profundo ya que las implicaciones reales de la Web y las nuevas posibilidades que ofrece, permiten a sus antiguas audiencias convertirse en productoras de material para programas, sitios Web, periódicos, etc. Además, la adopción por estas de equipos electrónicos de alta calidad, han llevado a que los medios investiguen nuevas formas para darles cabida dentro de sus publicaciones. Esto ha cambiado profundamente la percepción de la gente de quién tiene la autoridad para “saber” y “conocer” y sin duda, va a constituir también un gran reto para la educación.
|
|
http://www.elpais.com.co |
|
¿Qué lleva a la gente a publicar de manera individual o en colaboración con otros?. Existen varios motivos, uno de los principales es el económico, pero no menos importante es el de tener reputación, pues vivimos en una cultura pública donde “tener notoriedad es todo lo que importa” [3].
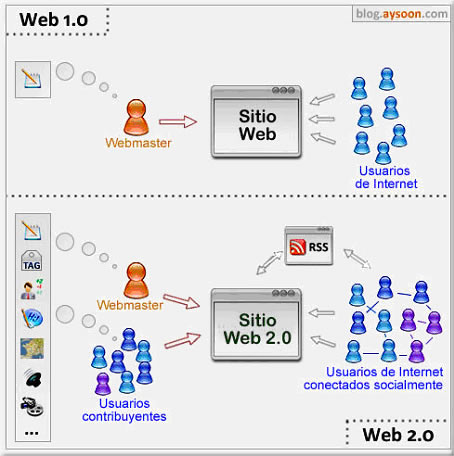
Ilustración publicada por
Aysoon sobre las diferencias entre la Web 1.0 y la Web 2.0
Algunos consideran que el incremento en el número de personas que generan y manipulan información y artefactos digitales es muy positivo. Otros son escépticos sobre la verdadera dimensión de la participación en todo esto y citan como ejemplo que de 13 millones de Blogs en Blogger (uno de los principales proveedores de Blogs), 10 millones se encuentran inactivos [4], deducen por lo tanto que esta gran masa de Blogs “muertos” constituye una poderosa razón para mantener el escepticismo sobre el extenso crecimiento de la “Blogosfera”.
2- APROVECHAMIENTO DEL PODER DE LAS MASAS
Este concepto encierra varios aspectos a considerar. El primero de ellos es el que se refiere al “aprovechamiento de la inteligencia colectiva” utilizado por el frecuentemente citado Tim O’Reilly, el cual tiene algunos problemas asociados. El primero de ellos ¿a qué tipo de inteligencia nos referimos? Y el segundo, equiparar inteligencia con información. O´Really resolvió esos problemas refiriéndose más bien a la “sabiduría de las masas (multitudes)” de la que habla en su libro, “Wisdom of Crowds”, James Surowiecki (columnista del periódico New York Times) y su aplicación a temas de la Web 2.0. Surowiecki se refiere a tres tipos de problemas que llama cognición, coordinación y cooperación y demuestra que estos pueden resolverse más efectivamente por grupos que operan en condiciones específicas, que por individuos, aún sean estos los miembros más inteligente de esos grupos. Se puede decir que su premisa principal radica en que las personas, actuando independientemente pero de manera colectiva, generan una “masa” que tiene mayores posibilidades que un individuo, para producir una respuesta correcta, dentro de ciertas circunstancias.
Y aunque Surowiecki no usó el ejemplo de la Web para demostrar sus conceptos si dijo que “la Web estructuralmente es apta para la sabiduría de las masas”. Este libro ha tenido mucha influencia en el estilo de pensamiento de la Web 2.0 y muchos de los que escriben sobre el tema han adoptado sus ideas cuando hacen los comentarios de sus observaciones sobre la Web y sobre las actividades basadas en Internet.
Uno de los primeros efectos visibles de esta “sabiduría de las masas” es el poder de convocatoria. Esto quedó demostrado el 4 de febrero de 2008 para Colombia y el mundo, cuando, según datos de los organizadores, 13 millones de personas en 183 ciudades de diferentes países marcharon en contra de las Farc, en respuesta a la convocatoria que a través del grupo de Facebook “Un millón de voces contra las Farc” se realizó durante un mes, a partir del 4 de enero. Al momento de escribir estas líneas, dicho grupo cuenta con 305.211 miembros.
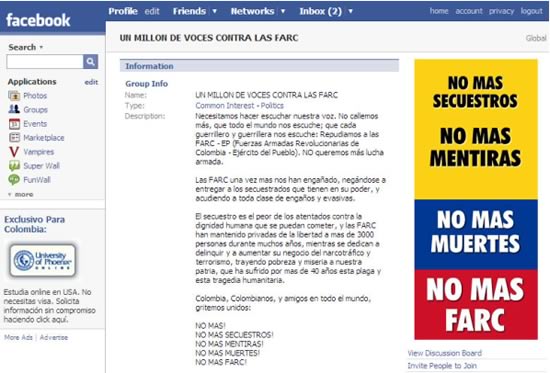
Grupo en FaceBook “Un millón de voces contra las Farc”
Seis días después de la marcha, el escritor peruano Mario Vargas Llosa publicó lo siguiente en una columna titulada “No más Farc”, en el diario El País de España:
“Esta es una historia que sólo podía haber ocurrido en nuestro tiempo y que muestra mejor que ningún ensayo científico la revolución cultural y política que ha significado para el mundo el Internet. Óscar Morales Guevara, ingeniero colombiano de 33 años, apolítico y residente en Barranquilla, irritado con la iniciativa del presidente venezolano Hugo Chávez de pedir a la Unión Europea que retirara a las Farc (Fuerzas Armadas Revolucionarias de Colombia) de su lista de organizaciones terroristas y las promoviera a la dignidad de guerrillas combatientes, quiso dejar sentada su protesta y se instaló ante su ordenador. Como miembro de Facebook, la más extendida red social de Internet, propuso crear, dentro de este espacio, la comunidad virtual ‘Un millón de voces contra las Farc’. [...] A las pocas horas varios centenares de personas se habían afiliado a su proyecto y en pocos días los adscritos eran millares. Las incorporaciones a la comunidad recién creada llegaron a alcanzar el ritmo de dos mil por hora. Uno de estos entusiastas, Carlos Andrés Santiago, un joven de 22 años de Bucaramanga, sugirió entonces la idea de la Marcha por la Paz del lunes 4 de febrero. Lo ocurrido ese día en casi todas las ciudades de Colombia y en muchas decenas de ciudades del resto del mundo, incluso en lugares tan sorprendentes como Bagdad, una aldea del Sáhara, Moscú y la capital de Ucrania, quedará como un hito para la historia moderna. No hay precedentes para esta extraordinaria movilización de millones de personas, en cinco continentes, en contra del terror y el embauque políticos encarnados por las Farc [...] esa movilización en favor de la paz y de la verdad [es un] ejemplo es extraordinario. No sólo ha servido a su país y a la decencia. Nos ha mostrado el arma poderosísima que puede ser la tecnología moderna de las comunicaciones si la sabemos usar y la ponemos al servicio de la verdad y la libertad”.
|
|
Por ejemplo, una persona X que pertenezca a una red social como LinkedIn, y cuente en esta con 334 contactos directos (relación directa - verde), podría llegar a tener 84.200 contactos producidos por sus contactos directos (relación indirecta - azul) y 3’465.100 contactos de tercer grado (esto es: amigos de los contactos indirectos de sus contactos directos). http://web2.socialcomputingmagazine.com/ |
|
El segundo, se refiere al Crowdsourcing término derivado del Outsourcing que utilizan las empresas para denominar los servicios que contratan por fuera de sus negocios, tales como: aseo, vigilancia, etc. Acuñado por el periodista Jeff Howe de la revista Wiredpretende conceptualizar el proceso de “contratación de servicios en la Web” dentro de la multitud de usuarios congregados en torno a Internet. Esto con el objeto de buscar soluciones a necesidades que van desde contenidos para medios y realización de tareas sencillas, hasta resolver problemas científicos; apuntando al empoderamiento del aficionado que lo realiza de manera gratuita o por una tarifa baja, pues lo que más le interesa es el reconocimiento y el orgullo implícitos en ser el seleccionado.
A nivel muy simple, el Crowdsourcing se construye sobre la popularidad de sitios Web que permiten compartir contenidos como Flickr y YouTube que posibilitan una segunda generación de sitios Web donde el contenido creado por los usuarios se pone a disposición para que otras personas lo reutilicen.
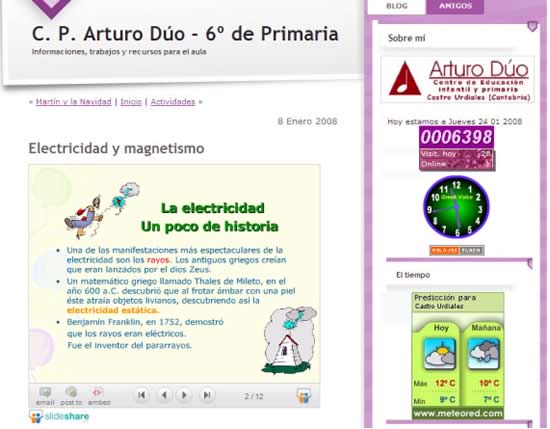
Presentación multimedia sobre la electricidad, almacenada en SlideShare,
pero desplegada en el blog del profesor Arturo Dúo
Otro ejemplo similar a Flickr y YouTube es SlideShare que permite almacenar presentaciones multimedia y luego desplegarlas en un blog o en una página Web cualquiera mediante un código “embebido” en ellos. Lo anterior resulta especialmente útil para los docentes ya que pueden guardar presentaciones, videos, fotografías, archivos de audio y documentos en sitios Web especializados para cada uno de estos formatos y luego, incluirlos muy fácilmente dentro de sus blogs personales.
Otro ejemplo de Crowdsourcing son las compañías que en los últimos años han usado sus sitios Web para reunir a sus clientes que enfrentan retos de investigación y desarrollo (I+D) en sus compañías con científicos independientes, amateurs o investigadores retirados. Así mismo, algunas compañías solicitan, a los miembros de estos grupos de investigadores, ideas para desarrollar nuevos negocios que luego se someten a votación para escoger las mejores. Esta última modalidad podría usarse para resolver problemas educativos o para plantear proyectos innovadores y retadores que enriquezcan el aprendizaje de los estudiantes.
El tercero lo constituyen las “Folksonomias” en las cuales aunque las personas actúan de manera individual producen resultados colectivos. Este término se le debe a Thomas Vander Wal, quien lo generó partiendo de sus experiencias en la construcción de sistemas taxonómicos y de su frustración por la pobre recuperación de información que hacían los usuarios, que no podían “adivinar” cuál era la palabra clave correcta que debían usar.
Sin embargo, Vander Wal ha expresado recientemente su preocupación por la mala aplicación del término aclarando lo siguiente: “Folksonomia es el resultado del etiquetado, individual y libre, de información y objetos (de cualquier cosa que tenga una URL), para la recuperación personal de información. Por otra parte, el etiquetado se hace en un ambiente social, compartido y abierto a otros. La acción de etiquetar la hace la persona que consume la información” y enfatiza que esto no es ni colaborativo ni constituye una forma de categorización [5]. Agrega que el valor de la Folksonomia se deriva de una parte, de que las personas usen su propio vocabulario para agregar valor explícitamente a la información o al objeto que están consumiendo, tanto en su carácter de usuarios como de productores, y de la otra, de tres elementos de los datos: la persona que etiqueta, el objeto etiquetado y la etiqueta que se adhiere a ese objeto.
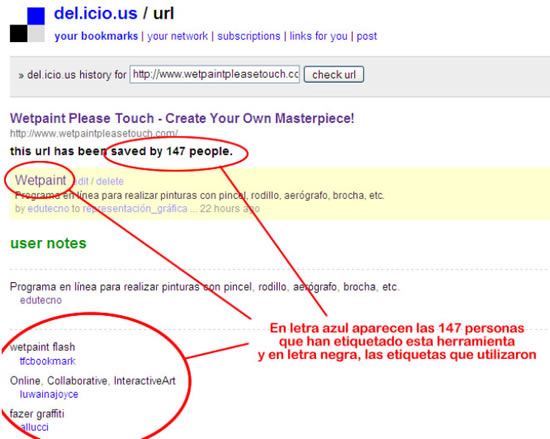
del.icio.us, sitio Web de Joshua Schacter, hizo despegar el fenómeno
del etiquetado social de contenido que facilita la Folksonomía.
Por ejemplo, si usted conoce la URL de un objeto, tal como una página Web, y le asigna a esta una etiqueta, puede encontrar otras personas que usen la misma etiqueta para marcar ese mismo objeto. Eventualmente, esto lo puede conducir a encontrar otras personas con intereses parecidos a los suyos o que compartan un vocabulario similar. Es en este punto en el que la Folksonomia encuentra su valor si se la compara con la taxonomía, ya que grupos de personas con vocabulario similar pueden funcionar como una especie de filtro humano de contenido para otros. Por otro lado, como las etiquetas se generan una y otra vez, es posible descubrir en ellas tendencias de intereses emergentes.
3-DATOS EN ESCALA ÉPICA
En esta era de la información se generan y utilizan permanentemente una creciente cantidad de datos. Auque para algunos estos nos están ahogando, en el universo de la Web 2.0 tanto los datos, como la cantidad de estos, desempeñan un papel crucial pues las compañías de esta nueva Web los capturan y convierten en ríos de información en los que se puede, por así decirlo, “pescar”.
Tim O’Reilly discutió el papel que los datos y su manejo han jugado en compañías como Google, argumentando que para los servicios que ellas prestan, “el valor del software es directamente proporcional a la escala y dinamismo de los datos que ayuda a manejar”. Estas son compañías que como competencia fundamental administran bases de datos y redes, que han desarrollado además la habilidad para recolectar y manejar datos en cantidades nunca antes vistas. Google tiene en la actualidad un total de bases de datos que se mide en cientos de pentabytes (un Pentabyte corresponde a 1.125.899.906.842.624 Bytes = 1.073.741.824 Gigabytes = 1.024 Terabytes) y que se incrementan considerablemente cada día.
Muchos de estos datos se recogen como efecto colateral del uso ordinario por parte de usuarios y agregadores que ingresan a sitios de Internet de alto tráfico tales como Google, Amazon o Ebay. Estos servicios tienen la particularidad de auto mejorarse o de “aprender” cada vez que se utilizan. Tomemos por ejemplo a Amazon que registra la escogencia que usted hace para comprar libros, la combinan con millones de otras escogencias para luego examinar y extraer de esos datos información que le permita hacer recomendaciones que por así decirlo “den en el blanco”. Este tipo de compañías recogen la sabiduría colectiva de los usuarios observando cuidadosamente lo qué hacen millones de ellos.
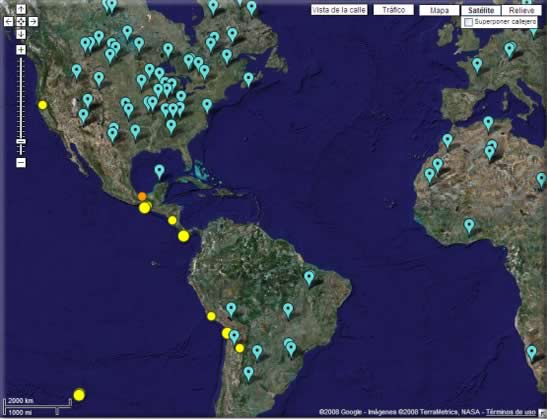
Además, muchos de estos datos también están disponibles para los desarrolladores, quienes los recombinan de nuevas maneras. Esto se conoce como “mash-up”; neologismo que parece provenir de la música y que se refiere a una aplicación Web híbrida que combina, dentro de una herramienta que las integra, datos provenientes de más de una fuente; de esta manera se genera un servicio Web diferente del que originalmente ofrecían las fuentes de donde proceden los datos. Por ejemplo, si tomamos el servicio de mapas de GoogleMaps y lo combinamos con fotos de Flickr, obtenemos un nuevo servicio al estilo de la Web 2.0.
|
|
En este mapa se puede apreciar claramente en qué consisten las llamadas Mash-ups: El mapa procede de Google Maps; los círculos representan los movimientos sísmicos registrados en los últimos 7 días (enero 17 al 23 de 2008) cuyos datos provienen de la respetada agencia gubernamental USGS; los símbolos azules representan los cráteres ocasionados por impactos de cuerpos celestes sobre La Tierra, datos puestos a disposición de toda la comunidad de Google Maps por un usuario de esta. |
|
La creación de estas aplicaciones (mash-ups) se facilita gracias a lo que se conoce en inglés como API (Interfaz de Programación de Aplicaciones) y que consiste en un conjunto de rutinas, protocolos y herramientas que facilitan el desarrollo de aplicaciones de software ya que ofrecen todos los insumos necesarios para generarlas.
|
|
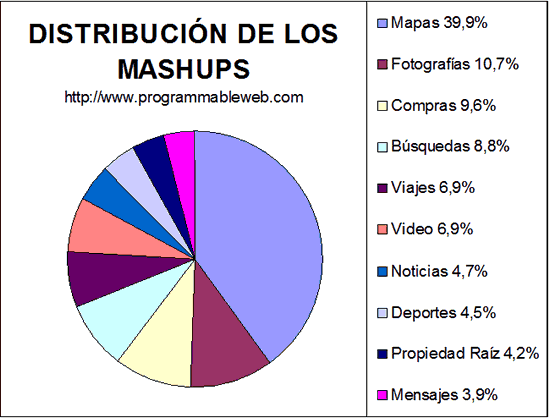
En esta grafica se puede apreciar la distribución de las 10 principales categorías de mashups. |
|
También te podría interesar
Diez ideas poderosas que moldearán el presente y el futuro de las Tecnologías de la Información en la Educación.
Ver artículoSembrando las semillas para una sociedad más creativa
Ver artículoReseña de software para Aprendizaje Visual
Ver artículoPeriódicos Escolares Digitales
Ver artículo
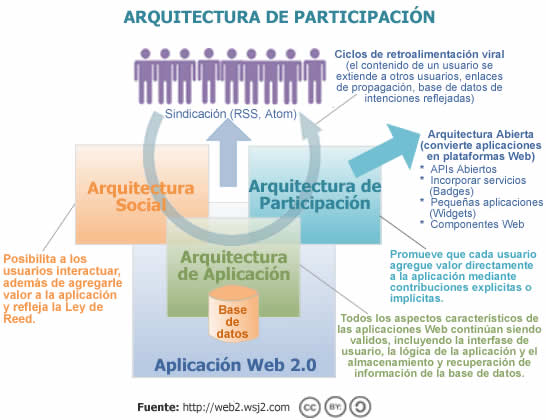
4- ARQUITECTURA DE PARTICIPACIÓN
Hace también parte del punto anterior, aunque en cierta forma tiene vida propia, la llamada Arquitectura de Participación, concepto sutil con el que se pretende expresar la idea de contenidos generados mediante la colaboración entre usuarios y la producción por parte de estos. Para entender el concepto es necesario darle el mismo peso a las dos palabras que lo conforman porque se trata tanto de arquitectura como de participación y, en su nivel más simple, significa que la forma en que un servicio está diseñado puede mejorar y facilitar la participación masiva en este por parte de los usuarios.
En un nivel más sofisticado la arquitectura de participación ocurre cuando mediante el uso normal de una aplicación o servicio, el servicio mismo mejora. Para el usuario parece ser un efecto secundario del uso del servicio pero lo que verdaderamente ocurre es que el sistema ha sido diseñado para tomar las interacciones de los usuarios y utilizarlas para auto mejorarse, como ocurre por ejemplo con las búsquedas en Google o lo que pasaba con el intercambio de canciones de Napster, en donde cada usuario ayudó de manera automática e implícita a construir una gran base de datos de canciones compartidas.
O’Really concluyó que “BitTorrent demostró un principio clave de la Web 2.0: que un servicio mejora mientras más personas lo utilicen”, en esto están implícitas una arquitectura de participación y una ética de cooperación inherente en la cual el servicio actúa en primera instancia como agente inteligente, conectando por los bordes a cada uno de los usuarios y “agarrando”, por así decirlo, el poder que generan los mismos.
Otros de los aspectos a considerar dentro de la arquitectura de participación son los de participación y apertura. Estos conceptos anteceden a la Web 2.0 y se originan en las comunidades de desarrolladores de software de código abierto. Estas comunidades se organizan de manera tal que las barreras impuestas a la participación son bajas y existe una valoración real de ideas y sugerencias nuevas que se adoptan por aprobación popular. Este mismo argumento se aplica a servicios Web que en muchos casos se ubican en determinadas partes de un sitio Web a manera de prueba para medir, en tiempo real, la reacción de los usuarios frente a ellos. Dependiendo de la reacción, el servicio se afina y se hace accesible desde cualquier parte del sitio o se descarta. Esto conduce a que cualquier idea o sugerencia no sea ni buena ni mala en sí misma ya que en la Web 2.0 es buena en la medida en que logre la aceptación y adopción por parte de los usuarios.
Según esto, los sitios o las aplicaciones más exitosos parecen ser, aquellos que estimulan la participación masiva y ofrecen una arquitectura (facilidad de uso, herramientas útiles, etc) que tiene barreras bajas y que por lo tanto permiten la participación. Como concepto de la Web 2.0, esta idea va más allá de abrir el código del software a los desarrolladores, busca abrir la producción de contenidos a todos los usuarios y ofrecer datos para que estos los puedan reutilizar y combinar en las llamadas mash-ups.
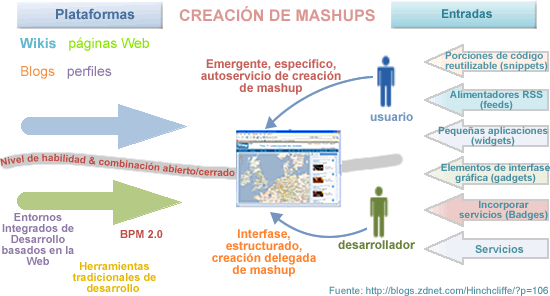
|
|
Los dos extremos del espectro del Mashup, la diferencia entre ellos radica en las plataformas que comúnmente utilizan usuarios y desarrolladores para reutilizar y combinar datos. |
|
5- EFECTOS DE LA RED, LEYES DE POTENCIA Y LA COLA LARGA (LONG TAIL)
Recordemos que la Web es una red de nodos entrelazados (documentos en HTML enlazados mediante hipertextos) y que en si misma está construida sobre las tecnologías y protocolos de Internet (TCP/IP, routers, servidores, etc.) que conforman la red de telecomunicaciones. Existen en el momento cerca de 1.200 millones de usuarios y a medida que estas tecnologías maduran y los usuarios toman conciencia de su tamaño y escala, las implicaciones de trabajar con este tipo de redes se empiezan a explorar en mayor detalle. Es muy importante para dimensionar lo anterior entender la topología tanto de la Web como de Internet, por lo que su forma e interconexiones se vuelven muy importantes.
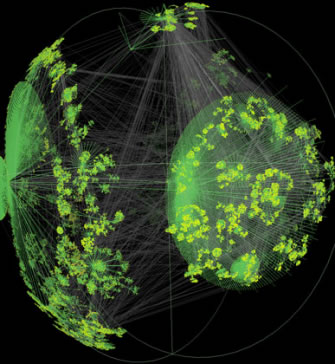
|
|
Esta topología de Internet muestra en marzo de 2001 cerca de 535.000 nodos de Internet y unos 600.000 enlaces. Fuente: Young Hyun, Cooperative Association for Internet Data Analysis [CAIDA] |
|
Existen dos conceptos clave que tienen relevancia en la discusión de las implicaciones de la Web 2.0. El primero tiene que ver con el tamaño de Internet o de la Web como red y más precisamente con las implicaciones económicas y sociales que tiene adicionar nuevos usuarios a un servicio basado en Internet; a esto se le conoce como Efecto de Red. El segundo concepto es la Ley de Potencias, conocida también como Ley Potencial, y las implicaciones que esta tiene para la Web. Lo anterior nos conduce a la discusión del fenómeno de la cola larga (Long Tail) [11]. Nombre coloquial de una distribución estadística que se aplica generalmente al comportamiento del mercado en la venta de productos. La cantidad de ventas de los productos más populares se encuentran concentradas en la parte izquierda de la gráfica (cabeza) y las de los menos populares se distribuye hacia la derecha (cola) con frecuencias que se aproximan a cero. En lo que respecta a Internet, esta herramienta se utiliza para mostrar que la mayoría del contenido de la Web es provisto por sitios Web pequeños [11].
El Efecto de Redes:
Para comprender mejor el punto anterior es importante entender a qué se hace aquí referencia. El efecto de Redes es un término de economía general usado para describir el incremento en el valor para los usuarios actuales de un determinado servicio que ofrece alguna forma de interacción con otros en el momento en que más y más personas comienzan a utilizarlo. El ejemplo que se usa más comúnmente para ilustrarlo es el de las telecomunicaciones. Cuando un nuevo usuario de teléfono se une a la red, no solo se beneficia él individualmente sino que hay otros usuarios que indirectamente también lo hacen ya que hay un número telefónico más al cual pueden marcar y hablar con alguien con quien antes no podían comunicarse telefónicamente.
|
|
Las aplicaciones Web 2.0 apalancan explícitamente el Efecto de Red |
|
Existe un paralelismo obvio entre las telecomunicaciones y el desarrollo de tecnologías sociales como la de My Space y más recientemente Face Book, en las que cada que una persona nueva se registra en estos sitios de redes sociales, los usuarios ya existentes se benefician también. Una vez que el efecto de Red comienza a tomar “momentum”, a incrementarse, y las personas se dan cuenta del aumento en la popularidad de un servicio, el sitio que lo ofrece despega por lo general muy rápidamente. El efecto perjudicial de esto es que muchas veces los usuarios se quedan “encerrados o bloqueados” en un producto o servicio. Uno de los ejemplos más citados de la primera situación es el de Office de Microsoft. A medida que más y más gente lo utiliza, porque otros ya lo hicieron y de esta manera pueden compartir documentos con un número cada vez mayor de personas, resulta cada vez más difícil cambiarse a otro producto pues esta acción daría como resultado disminuir el número de personas con las cuales se pueden compartir documentos. Se tiene la creencia en el mercado de las Tecnologías (TIC), que un producto tiene mayores posibilidades de resultar exitoso si gana tracción y momentum mediante su adopción temprana por parte de una masa crítica de usuarios.
Una de las implicaciones del efecto de red y del subsecuente “bloqueo” o encasillamiento dentro de algún producto tecnológico puede acarrear riesgos. Estos se pueden dar en los casos en que una aplicación de mala calidad o con tecnología deficiente o restrictiva tenga aceptación y adopción amplia e inclusive universal y genere el momentum que conduce a su adopción. Lo anterior sucedió con el formato de video cerrado subyacente en el Betamax, en contraposición con el abierto de VHS.
Como Internet es básicamente una red de telecomunicaciones, está sujeta a este Efecto de Red. Por lo tanto, se debe tener cuidado ya que en ocasiones se pone a disposición de los usuarios software con nuevos servicios que ofrecen características sociales, confiando la adopción de estos al Efecto de Red y no necesariamente a la utilidad o al valor de los servicios que presten.
¿Qué tan grande es realmente el Efecto de Red?: el problema con la Ley de Metcalfe.
Popularmente se cree lo que argumentó Robert Metcalfe, inventor de Ethernet [6] a comienzos de los años 70. Él estableció que el aumento de valor para una determinada red de telecomunicaciones, tipo Internet, era proporcional al cuadrado del número de usuarios de esta, es decir n2. A esto le llamó Efecto de Red.
Su idea original era conceptuar que aunque los costos de una red de comunicaciones aumentan de manera lineal (línea recta en una gráfica), el “valor” de esta para los usuarios aumenta en proporción a n2 y, por consiguiente, en algún punto de la gráfica estas líneas se cruzan. A partir de este cruce, el valor que tiene para los usuarios pertenecer a la red empieza a sobrepasar los costos que para ellos implica; lo que indica que se alcanzó masa crítica. Aunque Metcalfe la propuso como una fórmula empírica, rápidamente se acogió con ayuda de la descripción que de ella hizo en el año 93 el periodista de tecnología George Gilder quién la bautizó “Ley de Metcalfe”; y, como ese periodista tuvo bastante influencia durante la época del boom de las “punto com” de los años 90 [1], así se quedó.
Sin embargo, investigaciones recientes han desvirtuado tanto esta Ley como las teorías subsecuentes construidas sobre ella. Briscoe y otros autores [7] argumentan que estas formulaciones son incorrectas y que “el valor de una red de tamaño n crece en proporción a n multiplicado por el logaritmo de n: nlog(n). Crecimiento este que aunque considerable, es mucho más modesto que el atribuido a Metcalfe. Argumenta además que “mucha de la diferencia entre los valores artificiales de la época de las punto com y el valor real generado por Internet se puede explicar por la diferencia existente entre el optimismo desbordado de Metcalfe de n2 y la realidad mucho más sobria del nlog(n)”. De todas maneras, vale la pena recordar que el Efecto de Red tiene que ver directamente con el tamaño de esta.
Es importante reflexionar sobre lo profundamente arraigadas que están las ideas de Metcalfe. Mucho después, tanto del boom como de la explosión de la burbuja de las “punto com”, la idea de que existen “efectos especiales” que trabajan en Internet jalonados por la escala y la topología de una red sigue siendo poderosa y, esa idea, la consideran algunos sociólogos como una de las características que definen la revolución o el paradigma de la tecnología de la información [8].
Para entender lo anterior hay que hacerse a la idea de que como dice Briscoe [7], el término “valor” es bastante nebuloso y su significado no es tan claro para las personas: ¿Cuál es el valor real que tiene para un individuo, que otro ingrese a su misma red telefónica o que otro sitio Web se sume a los ya existentes en la Web?. Para entenderlo mejor debemos profundizar en la estructura de la Red y entender el valor de las leyes de potencias [11]que en ella operan.
¿Qué estructura tiene la Web?: el rol de las leyes de potencias [11]
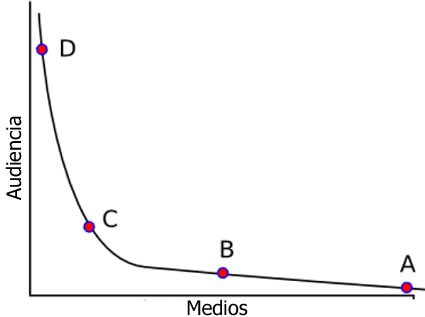
Además del efecto de Red, otro de los efectos característicos de las Redes es el llamado “Cola Larga” (long tail). La Cola Larga es el título de un libro escrito en 2006 por Chris Anderson, editor de la reconocida revista Wired. En él pretende demostrar las implicaciones sociales y económicas del hecho de que la distribución de muchos aspectos de la vida en la Web es desigual y que sigue una ley de potencias.

|
|
Cola Larga: distribución estadística que se aplica generalmente al comportamiento del mercado en la venta de productos. Las ventas de os más populares se encuentran concentrados en la parte izquierda de la gráfica (cabeza) y las de los menos populares se distribuyen hacia la derecha (cola) con frecuencias que se aproximan a cero. |
|
Para ayudar a entender este concepto, Anderson ofrece como ejemplo el proceso de la venta, en la Web, de discos de música al detal. Si se grafica el número de álbumes de música vendidos en una semana determinada, esto es, la frecuencia con la que se venden determinados álbumes, hace posible constatar que el lado izquierdo de la gráfica está dominado por las grandes ventas de álbumes populares o que ocupan los primeros lugares en aceptación y que se promocionan ampliamente por la radio. Con frecuencia, aunque no siempre, estos corresponden a álbumes nuevos. A medida que nos movemos hacia la derecha de la gráfica, las ventas caen dramáticamente aproximándose a la curva de potencias arriba descrita (ej: el segundo lugar en ventas corresponde a la mitad de la cifra alcanzada por el álbum que ocupa el primer lugar).; Solamente si no existen barreras artificiales en los almacenes para que las personas compren álbumes de música menos populares, la curva continúa cayendo largamente hacia la derecha de acuerdo con la regla del 1/n. Y es este el punto crucial señalado por Anderson, estas barreras incluyen variables como el espacio en las estanterías donde se exhiben los álbumes, no solo limitado sino costoso, lo que implica que únicamente los más populares o publicitados las ocupen. En el ambiente digital, carente de este tipo de límites porque en el espacio virtual no existen, se puede exhibir un número ilimitado de álbumes. Hasta ahora la presencia de barreras artificiales en los almacenes de música había encubierto la verdadera extensión de la cola larga.
Hacia el final de la cola larga las ventas son cada vez menores, de hecho, tienden a cero. Lo notado por economistas y analistas de ventas es que en la venta de álbumes de música, libros y otros artefactos, hasta los menos populares se venden en alguna proporción. Estos son los nichos que se encuentran al final de la cola larga. Pero lo que más los ha sorprendido es que la suma del número total de ventas en estos nichos menores de la cola alcanza cantidades sustanciales; así, individualmente los productos sean impopulares. De acuerdo con Anderson, en las ventas al detal tradicionales del año 2005, los álbumes musicales nuevos contribuyeron con el 63% de estas, pero cuando las ventas se realizaron en línea ese porcentaje retrocedió convirtiéndose en el 36%. Prueba de ello es Amazon, que ha utilizado la cola larga con resultados sorprendentes. También lo ha hecho Wikipedia, excelente exponente del concepto, pues tiene una cantidad de entradas que es decenas de miles mayor que las alcanzadas por cualquier enciclopedia impresa que se haya publicado.
Implicaciones de la topología de la Web:
¿Por qué es importante lo anterior? Porque tiene implicaciones para el desarrollo de la cola larga y es que nos estamos moviendo hacia una cultura y una economía donde un número muy considerable de personas participan en esos nichos específicos de la cola que realmente pesan. La especialización y los nichos de intereses específicos, además de la personalización y la fragmentación son todos susceptibles de ser jalonados por el avance hacia la derecha en la gráfica.
Una de las fuerzas que impulsan lo anterior es la “democratización” de las herramientas de producción. Para ilustrarla hacemos referencia a que el número de álbumes de música nuevos publicados en el 2005 se incrementó en un 36%, pero en el mismo lapso de tiempo se subieron a MySpace 300.000 canciones gratuitas, muchas de ellas producidas por aficionados. Esto demuestra que, de hecho, como dice Andersen “se está comenzando a dar el cambio de consumidores pasivos de contenidos a productores activos de estos” y a desarrollarse una cultura que el escritor Doc Searls llama “productivismo” (producerism) [9].
Respecto a los nichos específicos ocupados por nuevos productores de contenido (quienes en la Web 1.0 solo eran consumidores pasivos), hay un ejemplo ilustrativo publicado en el Blog de Omepet: Imaginemos por un momento que alguien tiene un Blog ubicado en el punto A de la cola larga con una audiencia cercana a cero. Esta persona escribe un artículo de opinión muy interesante y uno de sus pocos lectores lo comenta en su Blog personal ubicado en el punto B de la gráfica. Supongamos que dicho comentario, hecho en el punto B, lo lee alguien, se interesa, accede al artículo original y lo manda a un sitio como meneame [12] o a barrapunto [13], sitios que se encuentran en el punto C de la curva. Es en estos donde ingresa regularmente un redactor de noticias de prensa o de televisión que se da cuenta que dicho artículo existe y decide publicarlo como noticia en su medio informativo (D). De esta manera, la opinión publicada en A pasó de ser un grito solitario a ser conocida por una audiencia muy amplia (punto D); lo que representa una situación que antes no existía: que medios virtuales con poco tráfico cobren importancia y puedan influir en los de mayor audiencia, logrando que una noticia u opinión llegue a visibilizarse en medios a los que antes le hubiese sido imposible llegar.
6- APERTURA:
En la evolución de la Web se ha visto un amplio rango de desarrollos legales, regulatorios, políticos y culturales en torno al control, acceso y derechos del contenido digital. Sin embargo, la Web también ha tenido una tradición fuerte de trabajo abierto y esta sigue siendo una fuerza poderosa en la Web 2.0: estándares abiertos, software de código abierto, datos libres y espíritu innovador. Una tecnología importante en el desarrollo de la Web 2.0 ha sido el navegador de Internet Firefox, de código abierto, y con un sistema que agrega con facilidad y gratuitamente nuevas funcionalidades mediante extensiones (plug-ins), lo que permite la experimentación.
Exposición a los datos:
En general, la Web 2.0 enfatiza el uso de la información contenida en las enormes bases de datos que los diferentes servicios se ocupan de alimentar. De todas maneras la aparente tendencia hacia la apertura se atempera con el “tamaño épico” de los datos disponibles, recogidos y agregados por compañías comerciales de manera no estandarizada.
Se requiere un enfoque continuo tanto en el intercambio de datos abiertos como en la adopción de estándares abiertos; pues como lo expresó Tim O’Reilly en un foro de negocios en el 2006: “La verdadera enseñanza es que el poder puede no estar realmente en los datos mismos sino en el control al acceso a ellos”. Google no tiene datos sin procesar que no existan ya en la Web, pero lo que ha hecho es agregarles procesos inteligentes que facilitan usarlos para encontrar cosas.
Compartir datos es un tema bien importante para la Web 2.0. Lawrance Lessing [10] expuso recientemente la diferencia existente entre el “verdadero” compartir datos con el “falso” compartir, utilizando como ejemplo YouTube (ahora de Google) y dijo: “Pero el sistema nunca provee a los usuarios una manera fácil de llegar al contenido que otras personas han subido a la red”. Una situación similar se presenta con Blogger, el servicio de Blogs de Google. Otros servicios como Backpack y Wordpress son más permisivos y posibilitan que los datos de los usuarios se exporten como un archivo de texto XML.
APIs Abiertos:
Se conoce como API a la Interfaz de Programación de Aplicaciones que permite a los programadores utilizar una funcionalidad o un conjunto de módulos sin tener acceso al código fuente de estos. Una API que no requiere que los programadores paguen por ella una licencia o unos derechos se describe por lo general como abierta. Este tipo de APIs han ayudado a que se desarrollen rápidamente servicios en la Web 2.0 y han facilitado la generación de mash-ups que como ya dijimos es un neologismo que se refiere a una aplicación Web que combina datos provenientes de más de una fuente dentro de una herramienta híbrida que las integra.
Derechos de propiedad intelectual:
Tanto la Web 2.0, como el software de código abierto, están comenzando a generar efectos sobre los Derechos de Propiedad Intelectual (IPR, por su sigla en inglés) y sobre la forma en la que estos se perciben. Un ejemplo obvio es el papel que jugarán en el futuro los diferentes derechos de autor (copyright, creative commons, etc). Pues como lo señaló Chris Anderson, los “creadores” en el extremo derecho de la cola larga, que se han multiplicado considerablemente y que no esperan pago por sus contenidos, parecen haber resuelto de alguna manera entregar o renunciar a algunas de las protecciones que les confiere los derechos de autor. Al mismo tiempo la escala y alcance de los agregadores de la Web 2.0 da como resultado que esos sistemas pueden estar publicando de nuevo o reproduciendo material para el cuál la asignación de derechos de autor se ha obscurecido. Esta dicotomía se debe atender en el futuro.
NOTAS DEL EDITOR:
[1] Se denomina “Burbuja de las punto com” una corriente especulativa muy fuerte que se dio en las Bolsas de Valores entre los años 1997 y 2001. En ella, las empresas vinculadas al naciente sector de Internet y a la llamada Nueva Economía tuvieron un rápido y exagerado aumento de su valor en Bolsa. La especulación individual de inversionistas y la gran disponibilidad de capital de riesgo, se combinaron para crear un ambiente artificial. La crisis empezó cuando muchas de estas “punto com” empezaron a cerrarse, fusionarse o venderse, lo que llevó a la caída de Nasdaq y generó además de perdidas millonarias, la desaparición de miles de puestos de trabajo. Según algunos analistas económicos, la “nueva economía” nunca existió, todo se trató de una gran “burbuja” montada por algunos oportunistas para llenarse de dinero.
[2] BERNERS-LEE, Tim. 1999. Tejiendo la Red (Weaving the Web). Siglo XXI Editores http://www.sigloxxieditores.com/Libros/tejiendo_la_red.htm
[3] Tim Wu, Profesor de Leyes/Derecho, citado por Anderson en su libro “The Long Tail: How endless choice is creating unlimited demand”, 2006, página 74, Random House Business Books: London, UK.
[4] Charles Mann, Spam + Blogs=Trouble. Revista Wired, Edición 14.09, Septiembre de 2006, pp. 104–116 http://www.wired.com/wired/archive/14.09/splogs.html
[5] VANDER WAL, Thomas. 2005. Folksonomy definition and Wikipedia. Disponible en línea: http://www.vanderwal.net/random/entrysel.php?blog=1750 [ultimo acceso Ene/15/2008].
[6] Ethernet es una tecnología de Red utilizada en las redes de área local (LAN, por su sigla en inglés) por el cual se puede transmitir información a velocidades entre 10 y 1.000 Mbits por segundo, dependiendo del tipo de cable que se use: coaxial para el primero y fibra óptica para el más veloz.
[7] BRISCOE, B., ODLYZKO, A., Tilly, B. 2006. “Metcalfe’s Law is wrong”. Publicado en IEEE Spectrum, Julio de 2006. Disponible en línea: http://spectrum.ieee.org/jul06/4109 [último acceso: Enero 23 de 2008]
[8] CASTELLS, M. 2000. “La Era de la información”: Economía, sociedad y cultura, Volumen 1; Siglo XXI Editores. http://www.amazon.com/exec/obidos/ASIN/9682321689.
Primer volumen de la trilogía dedicado principalmente a examinar la lógica de la red, basándose en el análisis de la revolución tecnológica que está modificando la base de la sociedad a un ritmo acelerado.
[9] En términos generales, Productivismo (Producerism) hace referencia a una ideología que se contrapone a los movimientos que promueven la globalización económica y cultural http://en.wikipedia.org/wiki/Producerism
[10] Lawrance Lessing 2006. The Ethics of Web 2.0: YouTube vs. Flickr, Revver, Eyespot, blip.tv, and even Google. Publicado en el blog personal el 20 de octubre de 2006. Disponible en línea: http://lessig.org/blog/archives/003570.shtml [último acceso: Enero 23 de 2008]
[11] La Ley de potencias es una relación polinomial cuya escala no tiene varianza. Las más comunes relacionan dos variables y tienen la forma:
![]()
donde a (constante de proporcionalidad) y k (exponente de la ley de potencias) son constantes.
Un ejemplo de gráfica de Ley de Potencias se utiliza para demostrar posicionamientos de popularidad. A la derecha de la grafica se ubican los menos populares (cola) y a la izquierda los pocos que dominan (los más populares). Esta Ley se asocia con la distribución de Pareto, conocida como la regla de 80/20 (ejemplo: el 80% de las ventas corresponden al 20% de los clientes). http://es.wikipedia.org/wiki/Power_law
[12] Menéame (http://meneame.net/) es un sitio Web basado en la participación de los usuarios registrados quienes envían historias que otros usuarios del sitio (registrados o no) pueden valorar. Las historias más votadas se publican en la página principal. Se inspira en el modelo propuesto por digg.
[13] Barrapunto (http://barrapunto.com/) es un sitio Web que publica noticias relacionadas con el software libre, la tecnología y los derechos digitales. Se actualiza varias veces al día con breves resúmenes de notas publicadas en otros sitios Web con su respectivo enlace y además permiten al lector comentar dichas noticias.
CRÉDITOS:
Traducción realizada por EDUTEKA de apartes del Libro“What is Web 2.0? Ideas, technologies and implications for education" escrito por Paul Anderson y publicado por JISC (Joint Information Systems Committee). Descargue el reporte completo en formato PDF (inglés): http://www.jisc.ac.uk/media/documents/techwatch/tsw0701b.pdf
Publicación de este documento en EDUTEKA: Marzo 01 de 2008.
Última modificación de este documento: Marzo 01 de 2008.





